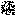01. ទារក Tesla
សូមក្រឡេកមើលឧទាហរណ៍ដ៏ពេញនិយមមួយពីអ៊ីននធឺណិត។
នៅក្នុងវីដេអូនេះ មុខរបស់ទារកត្រូវបានយកទៅដាក់លើមុខលោក Elon Musk ។ ប្រភេទនៃការប្តូរមុខនេះគឺជាការប្រើញឹកញាប់បំផុតនៃការក្លែងបន្លំជ្រៅ (deepfakes)។ មើលឱ្យជិត៖ ជ្រុងមុខក៏មិនត្រូវគ្នា ហើយពណ៌ស្បែកក៏ខុសគ្នា។

ការរក្លែងបន្លំជ្រៅត្រូវបានបង្កើតឡើងដោយកម្មវិធីកុំព្យូទ័រដែលអាចបង្រៀនខ្លួនឯងពីរបៀបបង្កើតមុខឡើងវិញដោយការវិភាគរូបភាពជាច្រើនរបស់មនុស្ស។ បន្ទាប់មក កម្មវិធីនេះនឹងត្រួតបន្ស៊ីគ្នាលើមុខដែលវាបានបង្កើតឡើងវិញនៅលើវីដេអូដែលមានស្រាប់ - ដូចជាម៉ាស់ឌីជីថល។ អ្នកអាចឃើញដាននៃម៉ាស់បែបនេះនៅក្នុងវីដេអូនេះ៖
Target Video
Deepfaked Video
វីដេអូគោលដៅការក្លែងបន្លំជ្រៅ៖ YouTube | AndrewSchrock | Cutest Baby Montage Ever.
ប្រភពវីដេអូរក្លែងបន្លំជ្រៅ៖ YouTube | TheFakening | Baby Elon Musk Montage Deepfake