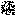01. Малятко Тесла
Погляньмо на популярний приклад з інтернету.
У цьому відео на обличчя немовляти наклали Ілона Маска. Така заміна обличчя — найбільш типове використання технології deepfake. Погляньте уважно: краї розмиті, а тон шкіри інакший.

Діпфейки створює комп’ютерна програма, здатна навчатися відтворювати обличчя за допомогою аналізу численних зображень людини. Далі програма накладає відтворене обличчя на наявне відео — це наче цифрова маска. Сліди такої маски можна побачити в цьому відео:
Target Video
Deepfaked Video
Відео, на яке наклали зображення: YouTube | AndrewSchrock | Cutest Baby Montage Ever.
Джерело: YouTube | TheFakening | Baby Elon Musk Montage Deepfake