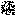01. Con trai của ông chủ Tesla
Hãy cùng xem một ví dụ phổ biến từ Internet.
Trong video này, khuôn mặt Elon Musk đã được phủ lên khuôn mặt của một em bé. Kiểu hoán đổi này là cách sử dụng deepfake phổ biến nhất. Nhìn kỹ, bạn sẽ thấy góc cạnh không sắc nét và màu da khác hẳn.

Deepfake được tạo ra bởi một chương trình máy tính có thể tự dạy cách tái tạo khuôn mặt bằng cách phân tích nhiều hình ảnh khác nhau của người đó. Sau đó, chương trình sẽ phủ khuôn mặt đã tái tạo lên một video sẵn có - như mặt nạ kỹ thuật số. Có thể thấy dấu vết của chiếc mặt nạ như vậy dưới đây:
Target Video
Deepfaked Video
Video đích deepfake: YouTube | AndrewSchrock | Cutest Baby Montage Ever.
Video nguồn deepfake: YouTube | TheFakening | Baby Elon Musk Montage Deepfake